📜 要約
### 主題と目的
本調査の主題は「ニューロモーフィックAI(Neuromorphic AI)」です。脳の情報処理原理を取り入れたハードウェア/アルゴリズム(とくにSNN: スパイキング・ニューラル・ネットワーク)を軸に、基礎技術、最新研究、主要プレイヤーとスタートアップ事例、市場・将来性を体系的に整理します。目的は以下の3点です。
- 現状の技術的な強み・限界を客観的に把握する(イベント駆動・インメモリ的計算・低消費電力などの要諦)。
- 代表チップ/アルゴリズムの進展や実証数値を通じて、実務での使いどころとリスクを明確化する。
- スタートアップ動向と市場の見通しから、採用のための現実的なロードマップ(PoC→量産)を提示する。
出典は本文中に明記し、研究結果の単なる羅列ではなく、用途設計に資する見解と判断材料を示します。
### 回答
#### 1. 基礎と主要技術(SNNの要点と従来AIとの違い)
- ニューロモーフィックAIは、スパイク(離散イベント)で情報を表現し、入力変化時だけ演算する「イベント駆動」を採るため、待機時の電力が極小化されます(出典: Wikipedia, Tutorialspoint, Ultralytics: https://en.wikipedia.org/wiki/Neuromorphic_computing, https://www.tutorialspoint.com/neuromorphic-computing/neuromorphic-computing-difference-from-traditional-computing.htm, https://www.ultralytics.com/glossary/spiking-neural-network)。
- メモリと計算を近接・統合してデータ移動エネルギーを抑える発想(インメモリ/メモリ密着計算)が中核です(出典: NatureレビューPDFミラー, IISc: https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
- SNNは時間情報(スパイク時刻)を活かし、疎な計算で低レイテンシ処理に強みがあります(出典: Ultralytics上の解説: https://www.ultralytics.com/glossary/spiking-neural-network)。
比較の要点(GPU/TPU系ANN vs ニューロモーフィック)
| 特徴 | 従来ANN(GPU/TPU) | ニューロモーフィック(SNN/専用チップ) |
|---|---|---|
| 計算様式 | 高密度な行列演算・同期処理 | イベント駆動・非同期・スパース計算 |
| 典型消費電力 | 数十〜数百W | mW〜W級、場合により100分の1オーダーの削減報告 |
| レイテンシ | 大規模処理で遅延・クラウド依存 | 低遅延・エッジ常時オンに適性 |
| 学習 | バッチ学習・勾配法が成熟 | STDP/擬似勾配/ANN→SNN変換など多流派 |
| 典型用途 | 大規模視覚・NLP・生成AI | エッジ監視、ロボティクス、異常検知、ウェアラブル |
出典: 解説記事/総説の整理(Data Engineer Academy, IJETT, Natureレビュー)
https://dataengineeracademy.com/blog/neuromorphic-vs-conventional-ai-a-data-engineering-tool-review/
https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf
https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf
学習法の要点
- STDP(スパイク時刻依存可塑性): オンライン学習や連続学習に適性(出典: https://www.geeksforgeeks.org/deep-learning/spiking-neural-networks-in-deep-learning-/, https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf)。
- 擬似勾配(surrogate gradient): スパイクの非微分性を近似してBP適用、近年の精度改善の鍵(出典: IJETT, Ultralytics)。
- ANN→SNN変換: 既存ANNをスパイク化して実用精度を狙うが、精度ロスやスパイク数増の調整が要点(出典: IJETT)。
#### 2. 代表チップ/アーキテクチャの比較
| チップ/組織 | 技術的特徴 | 強み・用途適性 | 主な論点 |
|---|---|---|---|
| Intel Loihi/Loihi2 | 多コアSNN、オンチップ学習対応 | 自律適応・ロボティクス・研究プロトタイプ | ツールチェーンは成熟途上(Lava等) |
| IBM TrueNorth | 低消費の大規模並列SNN ASIC | 常時稼働の低電力推論 | 学習・更新の柔軟性は限定的 |
| BrainChip Akida | エッジ指向の商用NSoC/IP | 製品組込み・オンデバイス学習 | SNN固有最適化の知見が必要 |
| BrainScaleS(Heidelberg) | アナログ/デジタル混在・高速エミュレート | 生物学的再現性・研究 | 量産・汎用化は困難(学術寄り) |
出典: Natureレビュー(Loihi, BrainScaleS)https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf、IJETT(TrueNorth)https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf、BrainChip公式 https://brainchip.com/
実証数値(注)
- IBM TrueNorth: 約100万ニューロン/2.56億シナプスを約70mWで動作する実験報告(出典: Wikipedia, 技術ブログ)
https://en.wikipedia.org/wiki/Neuromorphic_computing
https://code-b.dev/blog/neuromorphic-computing
- Loihi系: エネルギー遅延積で3桁改善の報告(出典: NatureレビューPDFミラー)
https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf
#### 3. 最新研究ハイライト(実験結果と意味)
- Eventprop+mlGeNN→Loihi2展開: GPU学習→量子化→Loihi2で、同タスクでJetson Orin Nano比 最大約10倍高速・約200倍省エネ(例: 0.19mJ vs 82.3mJ, 2.33ms vs 25.5ms)という結果を報告(出典: arXiv: https://arxiv.org/pdf/2503.04341)。
意味: SNNの「学習からデプロイ」までの実務パイプライン確立が進展。
- 学習可能遅延(learnable delays): 量子化SNNでも遅延学習でSHDベンチが44.41%→89.92%(閾値メカ込みで90.68%)まで向上(出典: CCN 2025アブスト: https://2025.ccneuro.org/abstract_pdf/Sun_2025_Long_delays_reduce_need_precise_weights.pdf)。
意味: 低ビット重みでも、時間表現の強化で性能を回復でき、低コストHW設計に追い風。
- BIASNN(生物学的注意): 少タイムステップ(例:4)で高精度・低スパイク、CIFAR-10で94.22%等を報告(出典: Nature Scientific Reports: https://www.nature.com/articles/s41598-025-22430-3)。
意味: エッジでの低遅延・省電力と精度の両立に有望。
- フォトニック実装: 電子系より桁違いの速度・帯域の可能性(VCSELベースLNPS等、サブns挙動)(出典: arXivレビュー: https://arxiv.org/html/2510.06721v2)。
意味: 長期的ブレークスルー候補だが、短期は研究/ニッチ向け。
学習可能遅延の効果(SHD抜粋)
| モデル | 精度 |
|---|---:|
| 全精度SNN(遅延なし) | 48.60% |
| 量子化SNN(遅延なし) | 44.41% |
| 量子化SNN+遅延学習 | 89.92% |
| 量子化SNN+遅延学習(閾値メカあり) | 90.68% |
出典: https://2025.ccneuro.org/abstract_pdf/Sun_2025_Long_delays_reduce_need_precise_weights.pdf
#### 4. スタートアップ事例(用途・指標・示唆)
| 企業 | 製品/技術 | 代表用途 | 主張・指標(出典) |
|---|---|---|---|
| BrainChip | Akida NSoC/IP | ウェアラブル、産業エッジ、車載補助 | オンデバイス学習・低電力を訴求(公式)https://brainchip.com/ |
| SynSense | Speck等 | ロボティクス、組立ライン | サブミリ秒級制御のデモ等(業界解説)https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/ |
| Prophesee | Metavision/DVS | 自動運転・ロボット視覚 | フレームカメラ比で早期検出(歩行者で+20ms等の報告)(同)https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/ |
| Intel(研究) | Loihi2 | キーワードスポッティング等 | Jetson Orin Nano比で最大10倍高速/約200倍省エネの事例(arXiv)https://arxiv.org/pdf/2503.04341 |
補足: DVS(イベントカメラ)は変化画素のみ出力し、低帯域・低電力・高ダイナミックレンジで高速シーンに強み(出典: Propheseeホワイトペーパー)https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf
#### 5. 市場・ロードマップ・標準化
- 市場フェーズ: 研究〜ニッチ商用の初期。チップ単体での規模感を示す指標として、2026年に約US$5.56億相当の推定が紹介されています(Natureレビュー内の整理。原典はレビューが参照する外部推計)(出典: https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
- エッジ投資の拡大が採用を後押し(出典: CIO)https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html
- ボトルネック: ツールチェーン未成熟、共通ベンチマーク不足(出典: Natureレビュー, IJETT)
https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf
https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf
段階的ロードマップ(技術・商用タスク)
| フェーズ | 期間目安 | 主要タスク |
|---|---:|---|
| 研究/プロトタイプ | 〜1–2年 | SNN設計、イベントセンサー実験、Loihi/Akida等でPoC準備 |
| 業界PoC(ニッチ) | 1–3年 | エッジ監視、ロボット制御、医療ウェアラブル等でE-D-A(Energy‑Delay‑Accuracy)検証 |
| 垂直市場拡大 | 3–5年 | センサー+チップ+SDKのバンドル商品化、評価基準・規格化 |
| ハイブリッド量産 | 5–10年 | エッジSNNとクラウドGPUの協調運用、インフラ最適化 |
出典: Natureレビュー, CIO, Prophesee/Vertiv資料
https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf
https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html
https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf
https://www.vertiv.com/en-asia/about/news-and-insights/articles/educational-articles/the-edge-of-intelligence--how-neuromorphic-computing-is-changing-ai/
#### 6. 導入の実務ガイド(PoCの勘所)
- 適用の初期判断
1) 常時オン/バッテリー/低遅延/データを出せない環境なら有望(出典: CIO, Vertiv)
https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html
https://www.vertiv.com/en-asia/about/news-and-insights/articles/educational-articles/the-edge-of-intelligence--how-neuromorphic-computing-is-changing-ai/
- PoC手順(推奨)
1) ユースケース選定(例: DVS×欠陥検知, VAD/ウェイクワード, バイタル異常検知)
2) 指標定義: E-D-A(mJ/推論, ms/応答, 精度%)
3) ツール選択: Intel Lava, PyNN, snnTorch などでSNN設計→量子化→デプロイ(出典: Natureレビュー)
4) ハイブリッド構成: 前段SNNで疎化→後段GPUで高次解析(出典: CIO)
- 技術的Tips(最新研究の活用)
- 学習→展開はEventprop等で“GPU学習→Loihi等”のルートを試す(出典: https://arxiv.org/pdf/2503.04341)。
- 省メモリ設計には重み量子化+学習可能遅延を検討(出典: https://2025.ccneuro.org/abstract_pdf/Sun_2025_Long_delays_reduce_need_precise_weights.pdf)。
- 少ステップ高精度が必要ならBIASNN系の注意導入も候補(出典: https://www.nature.com/articles/s41598-025-22430-3)。
参考フロー(概念図)
```mermaid
flowchart LR
A[イベントセンサー(DVS/音/バイタル)] --> B[SNN前処理(疎化/低遅延)]
B --> C{要件}
C -->|即応/省電力| D[エッジ完結(Loihi/Akida)]
C -->|高次解析| E[クラウドGPU/TPU]
B --> F[ログ(スパイク統計/E-D-A)]
```
### 結果と結論
- 技術的結論
- ニューロモーフィックAIは、イベント駆動・メモリ近接・疎な時間表現により、エッジで「低消費電力×低遅延」を実測で示しつつあります。Loihi2の事例ではJetson Orin Nano比で最大10倍高速・約200倍省エネの報告があり(特定タスク上)、DVSは早期検出と低帯域を実例で提示しています(出典: https://arxiv.org/pdf/2503.04341, https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf)。
- アルゴリズム面でも、擬似勾配・ANN→SNN変換に加え、「学習可能遅延」「注意機構(BIASNN)」などが精度と効率の両立を前進させています(出典: CCN/NatureSR)。
- 事業・市場の結論
- 現状はニッチ用途の商用初期段階。ツールチェーンとベンチマーク不足が普及の最大ボトルネックで、センサーとチップを束ねた“垂直ソリューション”が先に伸びます(出典: Natureレビュー, CIO)。
- したがって短期は「PoCでE‑D‑Aを定量化→ハイブリッド運用」で勝ち筋を作るのが現実的。具体的には、Prophesee×SNNでの高速欠陥検知、Akidaのオンデバイス学習によるウェアラブル長時間稼働、Loihi系での自律制御などが有力な第一歩です。
- 実務アクション(推奨)
1) 自社ユースケースでE‑D‑AのKPIを設定し、小さなPoCを3ヶ月スプリントで回す。
2) ツールチェーン(Lava/PyNN/snnTorch)と人材育成を並行して進める。
3) 重み量子化+学習可能遅延/注意機構など、最新研究の“少コスト高効果”要素を優先採用する。
出典(本文内に記載の主要URL)
- Neuromorphic基礎/総説: https://en.wikipedia.org/wiki/Neuromorphic_computing
- NatureレビューPDFミラー: https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf
- SNN/評価(IJETT): https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf
- エッジ応用(CIO): https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html
- Eventprop/Loihi2: https://arxiv.org/pdf/2503.04341
- 学習可能遅延: https://2025.ccneuro.org/abstract_pdf/Sun_2025_Long_delays_reduce_need_precise_weights.pdf
- BIASNN: https://www.nature.com/articles/s41598-025-22430-3
- Propheseeホワイトペーパー: https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf
- Vertiv(エッジインフラ): https://www.vertiv.com/en-asia/about/news-and-insights/articles/educational-articles/the-edge-of-intelligence--how-neuromorphic-computing-is-changing-ai/
- BrainChip公式: https://brainchip.com/
- 解説/比較記事: https://dataengineeracademy.com/blog/neuromorphic-vs-conventional-ai-a-data-engineering-tool-review/, https://www.ultralytics.com/glossary/spiking-neural-network, https://code-b.dev/blog/neuromorphic-computing, https://www.geeksforgeeks.org/deep-learning/spiking-neural-networks-in-deep-learning-/
必要であれば、想定ユースケース(業界・デバイス制約・精度要件)をいただければ、PoC実験計画(必要キット、データ、評価設計、工数とリスク)を具体化してご提案します。
🔍 詳細
🏷 ニューロモーフィックAIの基礎とSNN:原理・特徴・GPU/TPUとの比較
#### ニューロモーフィックAIの基礎とSNN:原理・特徴・GPU/TPUとの比較
はじめに — 要点の提示
ニューロモーフィックAIは「脳の設計原理をハードウェアとソフトウェアに取り込む」アプローチであり、スパイクニューラルネットワーク(SNN)を中心に、イベント駆動・メモリと計算の統合・超低消費電力という特徴を持ちます[0](https://en.wikipedia.org/wiki/Neuromorphic_computing)、[6](https://www.tutorialspoint.com/neuromorphic-computing/neuromorphic-computing-difference-from-traditional-computing.htm)。以下では原理からSNNの仕組み、GPU/TPU(従来のANN向けプラットフォーム)との対比、実証例・数値、実務上の示唆まで、出典を示しながら解説します。
#### ニューロモーフィックの設計原理(要点)
- イベント駆動型:入力が「スパイク(離散イベント)」として発生したときだけ演算が起こるため、待機時の消費電力が極めて小さい[6](https://www.tutorialspoint.com/neuromorphic-computing/neuromorphic-computing-difference-from-traditional-computing.htm)、[4](https://www.ultralytics.com/glossary/spiking-neural-network)。
- メモリと計算の同居(インメモリ/メモリ密着設計):フォン・ノイマン型の「メモリ⇄演算」ボトルネックを解消し、データ移動エネルギーを大幅に削減することを目指す[2](https://rubyroidlabs.com/blog/2025/11/future-of-ai-neuromorphic-computing/)、[50](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
- 高い並列性と耐障害性:多数のニューロン(処理単位)が分散して動作するため、局所故障に強い設計になりやすい[0](https://en.wikipedia.org/wiki/Neuromorphic_computing)。
#### SNN(スパイクニューラルネットワーク)の仕組みと学習法
SNNは「時間情報(スパイクのタイミング)」を情報源とする点でANNと根本的に異なります。ニューロンは膜電位を時間的に積分し、閾値を超えると短いパルス(スパイク)を発火します。この離散イベント処理が「疎(sparse)」かつ「時間に敏感」な計算を可能にします[4](https://www.ultralytics.com/glossary/spiking-neural-network)、[3](https://www.geeksforgeeks.org/deep-learning/spiking-neural-networks-in-deep-learning-/)。
主な学習法と実装上の工夫:
- STDP(Spike-Timing-Dependent Plasticity):スパイクの相対的な時間関係でシナプスを更新する生物学由来のルール。オンライン学習や連続学習に適している[3](https://www.geeksforgeeks.org/deep-learning/spiking-neural-networks-in-deep-learning-/)、[37](https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf)。
- Surrogate gradient(擬似勾配):スパイクの非微分性を扱うため、スパイク関数を微分可能な近似で置換してバックプロパゲーションを適用する手法。近年のSNN精度改善の鍵となっている[67](https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf)、[4](https://www.ultralytics.com/glossary/spiking-neural-network)。
- ANN→SNN変換:事前学習したANNをスパイク表現に変換することで実用精度を確保する流派も多い(ただし精度ロスやスパイク数増加が課題)[37](https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf)。
#### GPU/TPU(従来のANNプラットフォーム)との比較(要約)
下表は主要差分を整理したものです。出典は解説記事と総説を参照しています。
| 特徴 | 従来のAI(ANN:GPU/TPU) | ニューロモーフィック(SNN/専用チップ) |
|---|---:|---|
| 計算モデル | 行列演算・同期バッチ処理(高密度)[12](https://dataengineeracademy.com/blog/neuromorphic-vs-conventional-ai-a-data-engineering-tool-review/) | イベント駆動・非同期(スパース)[12](https://dataengineeracademy.com/blog/neuromorphic-vs-conventional-ai-a-data-engineering-tool-review/) |
| エネルギー効率 | 高速だが消費大(数十〜数百W) | 1〜3桁低い消費(mW〜W級、場合により100分の1程度)[22](https://www.vertiv.com/en-asia/about/news-and-insights/articles/educational-articles/the-edge-of-intelligence--how-neuromorphic-computing-is-changing-ai/)、[78](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf) |
| レイテンシ | 大規模処理は遅延あり(クラウド依存) | 低遅延、リアルタイム適性が高い[32](https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html) |
| 学習 | バッチ学習、勾配法に最適 | ローカル学習(STDP等)や擬似勾配で扱う[37](https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf) |
| 最適用途 | 大規模視覚認識、NLP、トレーニング集約タスク | エッジ、ロボット、常時オンセンシング、低消費の異常検知[23](https://rubyroidlabs.com/blog/2025/11/future-of-ai-neuromorphic-computing/) |
(表出典:比較記事・総説を基に作成[12](https://dataengineeracademy.com/blog/neuromorphic-vs-conventional-ai-a-data-engineering-tool-review/)、[37](https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf)、[78](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf))
#### 実証例と数値的指標(注目ポイント)
- Intel Loihiは「エネルギー遅延積(energy–delay product)」で従来ソルバに比べて3桁改善を示したと報告されており、大規模実装・オンチップ学習の可能性が示されています[78](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
- IBM TrueNorthは2014年に発表され、100万ニューロン・2.56億シナプスを70ミリワットで動作させる実験が報告されています[0](https://en.wikipedia.org/wiki/Neuromorphic_computing)、[56](https://code-b.dev/blog/neuromorphic-computing)。
- 学術比較では、Surrogate Gradient法で訓練したSNNがMNISTで約97.8%(ANNに近接)、CIFAR-10で85%台を示す報告があり、エネルギー面ではANNより90%以上の削減を示す評価もあります(多指標評価が重要)[67](https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf)、[34](https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf)。
- 実製品例:BrainChip(Akida)やProphesee(イベントベースビジョン)はエッジ用途で商用化の段階にあり、Propheseeのセンサーは1秒当たり1万フレーム相当のイベント処理を低消費電力で実現するとしています[22](https://www.vertiv.com/en-asia/about/news-and-insights/articles/educational-articles/the-edge-of-intelligence--how-neuromorphic-computing-is-changing-ai/)、[21](https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html)。
▼ 市場見通し(参照図)
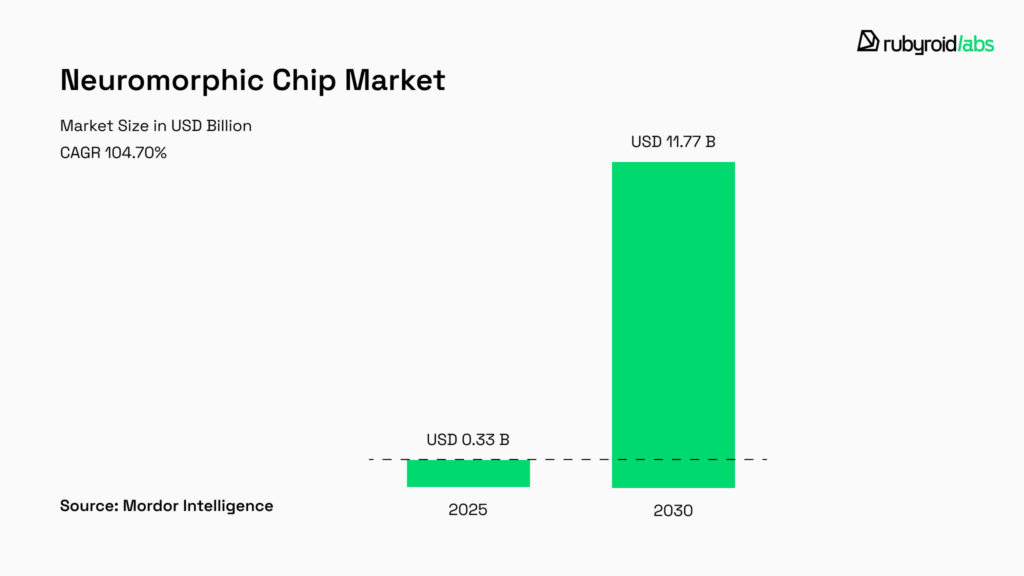
(出典:Rubyroid Labs / Mordor Intelligence引用のまとめ[2](https://rubyroidlabs.com/blog/2025/11/future-of-ai-neuromorphic-computing/))
また、「フォン・ノイマン vs 脳(メモリと計算の配置比較)」図も参考になります。
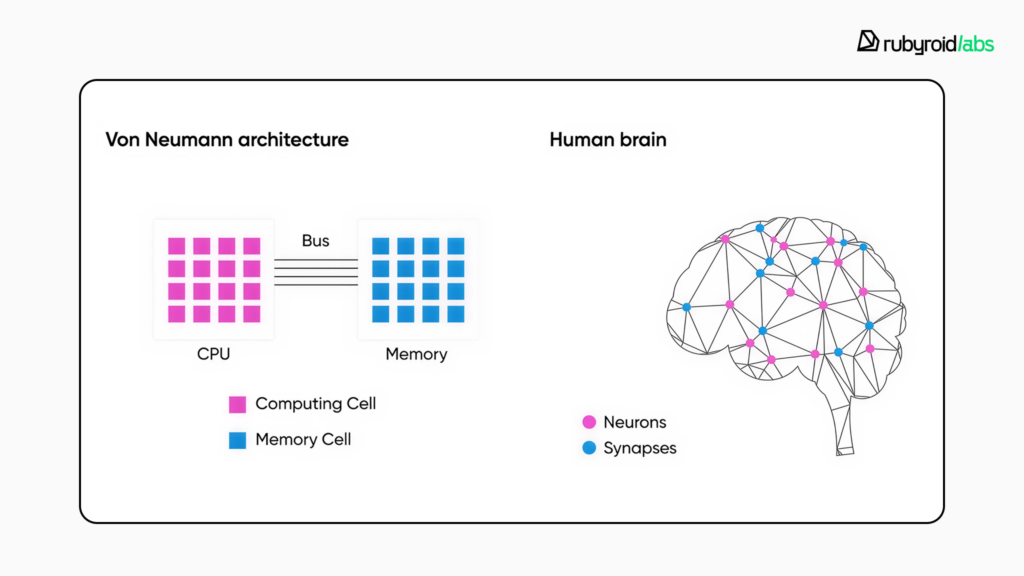
#### 実務的な示唆:いつ、どのように使うべきか(実践ガイド)
1. 適用検討の初期判断(スコーピング)
- 「常時オン」「バッテリー駆動」「低遅延応答」「データをクラウドに送れない/送りたくない」ケースはニューロモーフィックが有望と考えられます[23](https://rubyroidlabs.com/blog/2025/11/future-of-ai-neuromorphic-computing/)、[21](https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html)。
2. プロトタイプ戦略
- 小さなパイロット(例:イベントカメラ+SNNでの異常検知)を用いて「エネルギー・遅延・精度」を実測し、GPU実装とのTCO比較を行うことを推奨します(Nature総説も「Proof-of-concept重視」を推奨)[50](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
3. ツールと人材
- 現状はツールチェーンが未成熟(PyTorch/TensorFlowに相当する統一的エコシステム不足)であり、IntelのLava、Nengo、snnTorch、Loihi SDK、SpiNNakerやNESTなどの利用と並行して社内人材育成が必要です[50](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)、[12](https://dataengineeracademy.com/blog/neuromorphic-vs-conventional-ai-a-data-engineering-tool-review/)。
4. ハイブリッド化
- 高精度バッチ処理(大規模認識)はGPU/TPU、リアルタイム・低電力処理はニューロモーフィックに振り分ける「ハイブリッド」構成が現実的な初期採用パターンです[11](https://code-b.dev/blog/neuromorphic-computing)、[12](https://dataengineeracademy.com/blog/neuromorphic-vs-conventional-ai-a-data-engineering-tool-review/)。
#### まとめ(専門家の視点)
ニューロモーフィックAIは「エッジでの省電力・低遅延処理」という明確な強みを持ち、特定のユースケース(エッジ監視、ロボティクス、義肢制御、IoT異常検知など)で既に競争力を示しています。一方で、SNNのトレーニング手法や標準化されたベンチマーク、開発ツールの成熟が普及の鍵であり、まずは小規模なPoCで勝ち筋を作ることが現実的なアプローチです[37](https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf)、[50](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
補足:簡易フローチャート(mermaid)
```mermaid
flowchart LR
A[センサー(DVSなど)] --> B[ニューロモーフィックチップ (SNN)]
B --> C{用途判定}
C -->|リアルタイム/低電力| D[エッジ実装]
C -->|高精度バッチ| E[クラウド GPU/TPU]
```
参考文献(本文で参照した主要ソース)
- 基礎・総説: Wikipedia - Neuromorphic computing [0](https://en.wikipedia.org/wiki/Neuromorphic_computing)
- Nature総説「Neuromorphic computing at scale」[50](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)
- SNN実験・比較(IJETT)[67](https://ijettjournal.org/Volume-73/Issue-10/IJETT-V73I10P104.pdf)
- 実用化・市場動向(Rubyroid Labsまとめ)[2](https://rubyroidlabs.com/blog/2025/11/future-of-ai-neuromorphic-computing/)
- エッジ視点・事例(CIO記事)[21](https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html)
- SNN解説(Ultralytics)[4](https://www.ultralytics.com/glossary/spiking-neural-network)
- 比較記事(Data Engineer Academy)[12](https://dataengineeracademy.com/blog/neuromorphic-vs-conventional-ai-a-data-engineering-tool-review/)
もし具体的なユースケース(例:監視カメラの常時異常検知、ドローンのリアルタイム制御、ウェアラブルの生体信号監視など)を教えていただければ、PoC設計案(必要ハード/ソフト、評価指標、期待効果の数値化)を出します。
🖍 考察
### 調査の本質
ユーザーの依頼は「ニューロモーフィックAIをわかりやすくまとめる」ですが、本質的なニーズはもう一段深く、次の3点に集約されます。
1) **“何が新しく、どこで効くのか”を見極めたい**
GPU/TPUで動く従来AI(ANN)と比べて、ニューロモーフィック(主にSNN)はイベント駆動・スパース計算・メモリ近傍計算により、**低消費電力・低遅延**を狙います。しかし「万能に置き換える技術」ではなく、**制約条件(電力・帯域・遅延・プライバシー)が厳しい現場**で価値が出ます(例:エッジ常時監視、ロボット制御)[https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html](https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html)。
2) **研究が“製品化の手前”まで来ているのか知りたい**
研究としては、学習手法(surrogate gradient、Eventprop等)やデプロイパイプラインが整ってきており、Loihi 2でのエネルギー・遅延優位など、実測値も出ています[https://arxiv.org/pdf/2503.04341](https://arxiv.org/pdf/2503.04341)。一方、Natureの総説が強調する通り、**標準化・ツールチェーン不足**が普及のボトルネックです[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
3) **スタートアップ事例から“勝ち筋(導入の現実解)”を知りたい**
BrainChip(Akida)、SynSense(Speck)、Prophesee(イベントベースセンサ)などは、汎用AIの置換ではなく、**センサ×エッジ処理の垂直統合**で価値を出しています[https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/](https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/)。
### 分析と発見事項
調査結果から、ニューロモーフィックAIの現在地を「技術」「研究の突破口」「商用化パターン」「市場の見え方」の4つの観点で整理します。
#### 技術:強みは“計算そのもの”より「データ移動と待機電力を減らす設計思想」
フォン・ノイマン型のボトルネック(メモリ⇄演算のデータ移動)を避け、イベントが来たときだけ処理することで、常時オンのエッジで強い、という構図が一貫しています[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
#### 研究の突破口:SNNの弱点(学習しづらさ)を“実務パイプライン”で埋め始めた
- **Eventprop + mlGeNN → Loihi 2展開**の報告は象徴的で、GPUで学習しつつ、専用HWで効率良く回す「橋」が具体化しています。キーワードスポッティング等で、Jetson Orin Nano比で最大**10倍高速・約200倍低エネルギー**という結果が提示されています(同一タスク比較の報告値)[https://arxiv.org/pdf/2503.04341](https://arxiv.org/pdf/2503.04341)。
- 学習可能遅延や注意機構(BIASNN)などは、少ないタイムステップ・少ないスパイクで精度を上げる方向性で、**“低電力のまま精度も欲しい”**という製品要件に直結します[https://2025.ccneuro.org/abstract_pdf/Sun_2025_Long_delays_reduce_need_precise_weights.pdf](https://2025.ccneuro.org/abstract_pdf/Sun_2025_Long_delays_reduce_need_precise_weights.pdf)、[https://www.nature.com/articles/s41598-025-22430-3](https://www.nature.com/articles/s41598-025-22430-3)。
#### 商用化パターン:勝っているのは「単体チップ」より「センサ×用途の縦積み」
特に分かりやすいのがイベントベースビジョンです。DVS系は変化だけを出力するため、帯域・電力・遅延の面で“最初から有利なデータ形式”を作れます。Propheseeはイベントベースでの早期検出(例:歩行者検出が20ms速い等)を紹介しています[https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/](https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/)、白書[https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf](https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf)。
#### 市場:数字は成長を示すが、評価の単位が“チップ”に閉じると小さく見える
Natureレビューはチップ市場の見通し(例:2026年に約US$556.6Mという指標)を示しつつ、普及条件として標準化・ツール整備を重視します[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。一方、エッジ投資拡大が追い風になるという論点もあります[https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html](https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html)。
| 何が見えているか | 良いニュース | ただし条件 |
|---|---|---|
| 効率(電力・遅延) | 特定タスクで桁違いの実測報告が出ている[https://arxiv.org/pdf/2503.04341](https://arxiv.org/pdf/2503.04341) | 比較タスク/実装条件で結果が変わるため、自社PoCが必須 |
| 商用化 | Akida/Speck/イベントセンサ等、エッジ製品が存在[https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/](https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/) | “汎用置換”ではなく用途最適化が前提 |
| 普及の壁 | 課題が明確(ツール/標準/ベンチマーク)[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf) | エコシステムを自前で補う体制が要る |
### より深い分析と解釈
ここからは「なぜそうなるのか」を3段階以上掘り下げ、矛盾(高効率なのに普及しきらない)も含めて解釈します。
#### 1) なぜ“省電力・低遅延”で勝てるのか?(なぜの3段掘り)
- なぜ①:**イベント駆動**なので、入力変化がないとき計算しない(待機電力と無駄な演算が減る)。
- なぜ②:エッジの実システムでは、消費の大きな要因が「演算」だけでなく「データ移動・メモリアクセス」になりやすい。ニューロモーフィックはメモリと計算の密結合でここを狙う[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
- なぜ③:現場の価値は「平均性能」より「常時稼働の総エネルギー」と「反応までの時間」に現れる。だから、クラウド/GPUで高精度でも、通信・待機・熱設計を含めた全体最適では負ける場面がある[https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html](https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html)。
#### 2) なぜ普及が遅いのか?(効くのに広がりにくい矛盾)
- 解釈A(技術成熟の問題):**ツールチェーンと標準ベンチマーク不足**により、導入企業が「比較・検証・運用」をやりにくい。Natureが明確にボトルネックとして挙げます[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
- 解釈B(価値の出し方の問題):価値が出るのは「制約の強い現場」だが、その現場は業界ごとに要件が違い、水平展開しづらい。結果として“万能のプラットフォーム”になりにくい。
- 解釈C(比較の罠):GPU/TPUは成熟しており、精度・開発速度・人材が揃う。ニューロモーフィックは効率が高くても、**開発コスト(学習・移植・デバッグ)**が高いと、TCOで逆転することがある。だからPoCで「Energy–Delay–Accuracy」を揃えて比較する必要がある、という結論に収束します[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
#### 3) スタートアップが示す“現実解”は何か?(パターン分析)
スタートアップの勝ち方は概ね二類型です。
| 類型 | 代表 | 何で勝つか | なぜ成立するか |
|---|---|---|---|
| エッジ推論/学習チップ(処理側) | BrainChip Akida 等[https://brainchip.com/](https://brainchip.com/) | 省電力・オンデバイス処理 | バッテリー/熱/プライバシー制約が強い |
| イベントセンサ(入力側) | Prophesee[https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf](https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf) | そもそもデータを軽くする | 入力が疎なのでSNN/イベント処理と相性が良い |
重要なのは、どちらも「汎用AI市場」を正面から取りに行かず、**システムとして“制約”を解く**方向に寄せている点です。ここに導入の示唆があります。
### 戦略的示唆
ユーザーが「わかりやすくまとめる」ことを超えて、実際に意思決定・アクションにつながる形に落とすと、戦略は「PoC設計→ハイブリッド統合→垂直展開」が最も成功確率が高いです。
#### 1) まず狙うべき“キラー要件”を明確化する(導入判断の軸)
次のどれかが強いほど、ニューロモーフィックの採用合理性が上がります。
- 常時オン(待機時間が長い)
- バッテリー駆動/放熱が厳しい
- 低遅延(msオーダ)で反応が必要
- 通信できない/したくない(プライバシー/コスト/電波)
(背景:エッジ優位の整理[https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html](https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html))
#### 2) PoCは「精度」単独ではなく“三点セット”で勝負する
Nature総説の文脈に沿うと、PoCの合否は次の3つを同一条件で測れたかに依存します[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)。
1. 精度(Accuracy)
2. 遅延(Latency)
3. エネルギー(Energy)
これにより「GPUの方が精度が高いから終了」という早計を避けられます。特にEventpropのように、GPU学習→専用HWデプロイで大きく効率が変わるため、推論段の実測が重要です[https://arxiv.org/pdf/2503.04341](https://arxiv.org/pdf/2503.04341)。
#### 3) 実装戦略は“ハイブリッド前提”が現実的
短期の現実解として、以下の役割分担が堅いです。
- **学習(大規模・反復)**:GPU/クラウド
- **推論(常時オン・低遅延)**:ニューロモーフィック/エッジ
この構造は、研究と商用化の双方の記述と整合します[https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html](https://www.cio.com/article/4052223/neuromorphic-computing-and-the-future-of-edge-ai.html)。
```mermaid
flowchart LR
A[データ収集/教師データ作成] --> B[GPUで学習(ANNまたはSNN学習)]
B --> C[(必要に応じて)SNN最適化/量子化/変換]
C --> D[エッジにデプロイ(ニューロモーフィック)]
D --> E[常時オン推論:低遅延・低電力]
E --> F[重要イベントのみクラウド送信]
```
#### 4) スタートアップ/ベンダ選定の目利きポイント
- 「チップ」だけでなく、**SDK・評価ツール・リファレンス実装**が揃うか(ツール不足が最大課題のため)[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)
- センサまで含めた垂直統合(例:イベントカメラ)を提供できるか[https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf](https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf)
- 比較指標を“自社で再現可能”な形で出しているか(条件依存のため)
### 今後の調査
今回の調査は全体像と主要プレイヤーの把握に有効でしたが、「導入・投資・研究テーマ選定」に直結させるには追加調査が必要です。特に、標準化不足を前提に、**自分たちの比較軸を確立する調査**が重要になります。
追加調査が必要なテーマ(提案)
- ニューロモーフィックAIの評価指標の設計(Energy–Delay–Accuracyを自社PoCで再現する測定手順)
- Eventprop等「GPU学習→Loihi 2等デプロイ」パイプラインの再現性検証(タスク別の条件整理)[https://arxiv.org/pdf/2503.04341](https://arxiv.org/pdf/2503.04341)
- イベントベースビジョン導入時のシステム設計(同期、キャリブレーション、データ形式)[https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf](https://www.prophesee.ai/wp-content/uploads/2022/05/PROPHESEE-White_Paper_Event_Based_Vision_EN_05_09_2022.pdf)
- スタートアップ(BrainChip/SynSense/Prophesee等)の「実案件」ベース事例の深掘り(どの制約で導入が決まったか)[https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/](https://www.embedur.ai/how-neuromorphic-chips-could-redefine-edge-ai-devices/)
- ツールチェーン/標準化の最新動向の継続モニタリング(Natureが挙げる普及ボトルネックの改善度合い)[https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf](https://labs.dese.iisc.ac.in/neuronics/wp-content/uploads/sites/16/2025/01/s41586-024-08253-8.pdf)
- (長期)フォトニクス系ニューロモーフィクスの実装課題と適用ニッチの整理[https://arxiv.org/html/2510.06721v2](https://arxiv.org/html/2510.06721v2)
必要なら、想定ユースケース(例:工場の異常検知、ドローン回避、医療ウェアラブル、監視カメラの省電力化)を1つ教えてください。上の「三点セット指標」に基づき、PoCの評価設計(測るべき数値、比較対象、成功条件)まで具体化して提案します。
📚 参考文献
参考文献の詳細は、ブラウザでページを表示してご確認ください。