📜 要約
### 主題と目的
Attention Is All You Need(=Transformer)の「注意(Attention)機構」が、文章生成の始まりから終わりまで具体的にどのように働くかを、中高生にも分かるように平易に、かつ技術的に正確に説明することが目的です。特に次を明確にします:
- 入力(読む段階)で注意が何を作るか(エンコーダーの自己注意)
- 生成(書く段階)でどの注意がどのように使われるか(デコーダーのマスク付き自己注意とクロス注意)
- Query/Key/Value とマルチヘッドが「始まり→中盤→終わり」でどのように役立つか
- 実際に観察・実験する際のポイント(可視化や計算上の注意点)
参考にした図解・解説(学習に便利):
- Jay Alammar の図解(Transformerの全体像): https://jalammar.github.io/illustrated-transformer/
- Attention の計算フロー解説(例・図): https://vitalflux.com/attention-mechanism-workflow-example/
- 計算量や直感的説明(DataCamp): https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition
---
### 回答
まずは直感(やさしい比喩)から。Attention は「AIの視線(ルーペ)」です。文章を読むとき、人は「ここを見る」「あそこをもう一度見る」といった判断をします。Transformer はその「どこを見るか」を数値で決め、必要な情報だけを集めて使います。以下で「始まり→中盤→終わり」を段階的に説明します。
1) 基本要素の簡単な説明(Q, K, V と多頭注意)
- Query(Q)=今欲しい情報を表す「問い」
- Key(K)=各単語が持つ「ラベル」や手がかり
- Value(V)=実際の「中身」や情報
Query と全ての Key を比べて、どの Value をどれだけ使うか(重み付け)を決めます。詳しい計算は QK^T / sqrt(d) → softmax → Σ(weight · V) です(直感は上の「視線」)。
2) エンコーダー(入力を読む)で始まりに働く仕組み
- 入力文の各単語をベクトルに変換し、位置情報(どの順番か)を加えます。
- エンコーダー内部の自己注意は、各単語が文中の他の単語とどう関係するかを一度に全体を見渡して決めます。これにより「代名詞の指す相手」や「離れた単語の関係」を正しく捉えられます。
- マルチヘッド(複数の視点)により、意味的なつながり・文法的なつながりなどを同時に検討できます。
(参考: Jay Alammar 図説 https://jalammar.github.io/illustrated-transformer/)
3) デコーダー(生成するとき)の主な注意の種類と役割
- マスク付き自己注意(Masked Self-Attention)
生成中は「未来の単語を見ない」必要があります。デコーダーは既に生成した単語だけを参照して次を決めるため、未来情報をマスクします。これが「一語ずつ左→右に書いていく」仕組みを保証します。
- クロス注意(Encoder‑Decoder Attention)
生成の各ステップで、デコーダーはエンコーダーの出力(入力文の文脈ベクトル群)を参照し、「今どの入力部分を参照すべきか」を決めます。これにより生成が入力に忠実になります。
(参考図: https://jalammar.github.io/illustrated-transformer/)
4) 生成の「始まり→中盤→終わり」を8ステップで追う(実際の繰り返し処理)
番号リストで流れを示します(1回の生成ステップがこのサイクル):
1. デコーダーに開始記号(<SOS>)または既生成のトークンが入る。
2. その位置に対して埋め込みと位置エンコーディングを作る。
3. マスク付き自己注意で「これまで生成した語」から文脈をまとめる(未来は見ない)。
4. マルチヘッドが複数視点で文脈を補足する。
5. クロス注意でエンコーダーのどの入力情報が役立つかを照合する。
6. 得られた文脈をFFNで変換し、語彙ごとの確率分布を出す。
7. 確率に基づいて次の単語を選ぶ(argmaxやサンプリング)。
8. 選ばれた単語を生成列に追加し、<EOS>が出るまで繰り返す。
この「生成→参照→生成」の繰り返しにより、冒頭で得た情報を必要なときに何度でも再参照し、文全体の一貫性を保ちます(詳しいワークフロー解説: https://vitalflux.com/attention-mechanism-workflow-example/)。
5) 見出し的整理(始まり/中盤/終わりでAttentionが果たすこと)
以下の表は、生成の段階ごとに注意機構が何をしているかを要約します。
| 段階 | Attentionの役割 |
|---|---|
| 始まり(最初の単語を決める) | エンコーダーの文脈ベクトルを参照して最初の語を意味的に合わせる(入力全文が既に「整理」されている) |
| 中盤(文が長くなるとき) | デコーダーのマスク付き自己注意でこれまでの文脈整合性を保ちつつ、クロス注意で入力に忠実な情報を逐次取り込む |
| 終わり(要約や結論を出すとき) | エンコーダーの多層的表現を参照して「重要情報を残す/要約する」判断に寄与する |
(表の元となる解説: https://jalammar.github.io/illustrated-transformer/、https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition)
6) 具体例(短い例で直感を補強)
例文: "The cat sat on the mat. It was tired."
- “It” を処理するとき、デコーダー(あるいはエンコーダーの自己注意)は "cat" の Key と Query を高く一致させ、Value(cat に関する情報)を強く取り込みます。これで “It = cat” の解釈が生まれます(図解: https://jalammar.github.io/illustrated-transformer/)。
7) 観察と実験の勧め(中高生ができること)
- 注意重みを可視化することで「どの語がどの語を参照しているか」が見えます。まず短文で試すと変化がわかりやすいです(参考: https://jalammar.github.io/illustrated-transformer/、https://vitalflux.com/attention-mechanism-workflow-example/)。
- Colab や簡易 Transformer 実装を動かし、生成の各ステップでエンコーダー・デコーダー注意とデコーダー自己注意のマップを出して比べてみてください。
8) 限界と注意点(重要)
- 注意重みの可視化は解釈のヒントになりますが、「注意重み=完全な説明」ではありません。多層・多ヘッドの組合せで最終出力に至るため、単純化しすぎると誤解します(詳細: https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition)。
- 計算コストはトークン長の二乗に比例する(O(n^2))ため、非常に長い文章では工夫(スパース注意など)が必要です(参考: https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition)。
9) 処理フロー(簡易図)
以下はエンコーダー→デコーダーの生成サイクルを示す簡単な図です。
```mermaid
flowchart LR
E["入力文(エンコーダー)"] -->|文脈化(自己注意)| ED["エンコーダー出力"]
Dstart["<SOS>(デコーダー開始)"] --> DS["デコーダー自己注意(マスク有)"]
DS --> EDAT["クロス注意(エンコーダー出力を参照)"]
EDAT --> OutStep["次の単語を生成"]
OutStep --> DS
```
---
### 結果と結論
主要な結果と結論を簡潔にまとめます。
- Attention は「どこを見るかを動的に決める仕組み」であり、Q/K/V による重み付けで文脈を抽出する。これにより同じ単語でも文脈に応じた意味づけが可能になる(参照: https://jalammar.github.io/illustrated-transformer/)。
- エンコーダーの自己注意は入力を文脈化し、生成の「出発点(最初の単語)」を安定させる基盤を作る。デコーダーのマスク付き自己注意は生成の整合性(未来を見ない)を保ち、クロス注意は入力情報を逐次的に参照して意味の忠実性を担保する。これらが組み合わさることで「始まりから終わりまで一貫した」文章生成が実現する。
- 実務的には、注意重みの可視化は学習・デバッグに有用だが解釈には限界があり、さらに計算コスト(O(n^2))が長文処理の制約要因となる(参照: https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition)。
- 学習を深めたいなら、Jay Alammar の図解(https://jalammar.github.io/illustrated-transformer/)や Vitalflux のワークフロー図(https://vitalflux.com/attention-mechanism-workflow-example/)をなぞりつつ、小さな実装で注意マップを可視化する実験が最も理解を早める方法です。
必要なら、短い日本語の例文を使って「各生成ステップでの注意重み」を可視化するサンプルコード(Colab ノート)と図を用意します。どの例文(短文・翻訳・要約など)で試したいか教えてください。
🔍 詳細
🏷 導入:Attention Is All You NeedとTransformerの全体像
#### 導入:Attention Is All You NeedとTransformerの全体像
「Attention Is All You Need」は、AIが言葉を扱う仕組みを大きく変えた論文で、ここで提案されたTransformerという設計が現在の多くの大規模言語モデル(LLM)の基礎になっています[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)、[https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db](https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db)。簡単に言うと、この論文は「文章の処理で『どこを見るか(=注意)』をモデルに学ばせることで、長い文章でも正確に素早く扱えるようにする」アイデアを中心にしています[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)。
まず全体像をつかむためのキーワードは次の三つです:エンコーダー(読む部位)、デコーダー(書く部位)、注意機構(どこを重視するかを決める仕組み)。エンコーダーは入力文を「文脈を反映した表現」に変換し、デコーダーはその表現を参照しながら一語ずつ出力を作ります。このとき中心に働くのが「注意(Attention)」です[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)、[https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition](https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition)。
言い換えると、注意機構は「AIの視線」で、文章のどの単語にどれだけ視線を向けるか(=重み)を決め、その重みに応じて情報を集め直すことで、単語の意味を文脈ごとに柔軟に変えられます。これによって、同じ単語でも文脈に応じた解釈が可能になります[https://vitalflux.com/attention-mechanism-workflow-example/](https://vitalflux.com/attention-mechanism-workflow-example/)。
下の図は「注意の処理イメージ」で、実際の計算はQuery/Key/Valueというベクトル同士の類似度計算→Softmaxで正規化→Valueの重み付き和という流れになります(技術的な式はQK^T / sqrt(d) → softmax → Σ(weight·V))[https://nihar-palem.medium.com/understanding-attention-mechanisms-3e170de3eae8](https://nihar-palem.medium.com/understanding-attention-mechanisms-3e170de3eae8)、[https://vitalflux.com/attention-mechanism-workflow-example/](https://vitalflux.com/attention-mechanism-workflow-example/)。
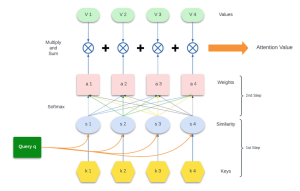
(注意処理のワークフロー例)出典: Vitalflux [https://vitalflux.com/attention-mechanism-workflow-example/](https://vitalflux.com/attention-mechanism-workflow-example/)
次に、文章生成の「始まりから終わりまで」注意機構がどのように働くかを、エンコーダーとデコーダーという観点で具体的に説明します。
1) 文章生成の「始まり」:入力を読む(エンコーダーの役割)
- 入力文の各単語はまず数値ベクトル(埋め込み)に変換され、位置エンコーディングで単語の順序情報も加えられます。これは並列処理でも順序を失わないための工夫です[https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db](https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db)、[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)。
- エンコーダー内部の自己注意(self-attention)は、各単語が文中の他の単語とどれだけ関係があるかを全体を見渡して決めます。これにより、「それ」が何を指すのか、長距離の依存関係(文頭と文末が結びつくような関係)も正確に扱えるようになります[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)、[https://vitalflux.com/attention-mechanism-workflow-example/](https://vitalflux.com/attention-mechanism-workflow-example/)。
- また「多頭(multi‑head)注意」は、異なる視点で並行して注意を計算することで、意味の多様性(たとえば銀行=川か金融か)を同時に捉えられるようにします[https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db](https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db)。
2) 文章生成の「途中〜終わり」:一語ずつ生成する仕組み(デコーダーの役割)
- デコーダーは「マスク付き自己注意」を使って、生成済みの単語だけを見て次の単語を決めます。未来の単語を見てしまわないようマスク(目隠し)することで、公平に逐次生成ができます[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)、[https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db](https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db)。
- さらに「エンコーダー・デコーダー間のクロス注意(cross‑attention)」が、デコーダーの今の生成状態(Query)とエンコーダーの出力(Keys/Values)を照合し、入力のどの部分を参照すべきかを決めます。これにより翻訳や応答が元の意味に忠実になります[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)、[https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db](https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db)。
- この「生成→参照→生成」を繰り返して、文末を示す特別な記号(<EOS>)が出るまで単語をつなげていきます[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)。
技術的な流れを、より平易に「8ステップ」で追うと理解が深まります。たとえば “The cat sat on the mat” の例では、ある単語(例:sat)をQueryにして、他単語のKeyと比較→Softmaxで注目度を確率化→Valueを重み付けして合算、という一連の8段階の処理が行われ、最終的に文脈を反映した表現(Attention Value)が得られます[https://vitalflux.com/attention-mechanism-workflow-example/](https://vitalflux.com/attention-mechanism-workflow-example/)。
なぜこの仕組みが「始まりから終わりまで」有効なのか——専門家の視点での洞察は次の通りです。
- 注意機構は「どこを参照するか」を動的に決めるため、入力の重要箇所を途中で忘れず最後まで参照できる。つまり長い文章でも最初と最後の情報を結びつけられると考えられます[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)、[https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition](https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition)。
- マスク付き自己注意により、生成過程の整合性(未来の単語を参照しない一貫した生成)が保たれるため、出力が連続した自然な文になることが示唆されています[https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db](https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db)。
- 多頭注意や層を重ねることで、単語レベルの細かい関係(局所)と文全体の意味(大域)を同時に取り扱える点が、従来のRNN系モデルより優れていることを示しています[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)。
一方で避けて通れない課題もあります。注意計算は入力中の全トークン対全トークンを扱うため、長い文では計算量が二乗増になるという計算負荷の問題があること、また多数のヘッドや層を持つモデルの内部挙動を完全に解釈するのは難しい点が指摘されています[https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition](https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition)。これらは研究・実装上のトレードオフだと考えられます。
最後に、実践的なおすすめ:理解を深めたい場合は、視覚的で丁寧な解説を読むのが最短です。Jay Alammarの「The Illustrated Transformer」は図解が充実しており[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)、VitalfluxやMediumの解説記事は注意の計算フローを段階的に示してくれます[https://vitalflux.com/attention-mechanism-workflow-example/](https://vitalflux.com/attention-mechanism-workflow-example/)、[https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db](https://luv-bansal.medium.com/transformer-attention-is-all-you-need-easily-explained-with-illustrations-d38fdb06d7db)。図をなぞりながら小さな実装ノート(Colab上の簡単なTransformer)を動かすと、「始まり→理解(エンコーダー)→生成(デコーダー)」の流れがぐっと実感できます。
まとめると、Attentionは単に計算のトリックではなく、「AIが文章のどこに注目するかを動的に決める羅針盤」の役割を果たし、入力を正しく理解する出発点から、出力を一貫して作り上げる終点まで、文章生成の全行程を支えていると考えられます[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/)、[https://vitalflux.com/attention-mechanism-workflow-example/](https://vitalflux.com/attention-mechanism-workflow-example/)、[https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition](https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition)。
🖍 考察
### 調査の本質
ユーザーの本質的な関心は、「Attention Is All You Need(Transformer)の注意機構を中高生でも理解できる形で説明してほしい」、特に「注意が文章生成の始まりから終わりまでどのように役立つか」を知りたい、という点にあります。価値提供のポイントは次の三つです。
1) 概念を直感と比喩でかみくだき、学習者が自分で“注意の動き”を追えるようにすること。
2) 生成プロセス(開始→途中→終了)で注意が具体的に何をしているかを可視化・実験可能な手順で示すこと。
3) 教育・実務で試せる実践的なワークプランと、研究的視点での留意点(計算コストや解釈の限界)を提示すること。
真のニーズは「抽象的な数式や黒箱ではなく、実際の例と手を動かす実験で注意の『働き』を体感したい」という学習目標にあります。
### 分析と発見事項
1. 基本メカニズム(要約)
- 注意は「Query(今の問い)」「Key(候補のラベル)」「Value(取り出す情報)」の仕組みで動き、QueryとKeyの類似度でどのValueをどれだけ使うかを決めます(数式:softmax(QK^T / sqrt(d_k)) V)。この仕組みにより任意の位置の情報を直接参照でき、長距離の依存関係を扱えます(参考:[The Illustrated Transformer](https://jalammar.github.io/illustrated-transformer/)、[Vitalflux](https://vitalflux.com/attention-mechanism-workflow-example/))。
- マルチヘッド注意は「複数の視点で同時に注目」を行い、語義や構文など別々の関係を同時に捉えます。
2. 生成開始→途中→終了での役割分担(発見)
- 始まり:エンコーダーの自己注意で入力が文脈化されるため、デコーダーは最初の単語を決める段階から文全体の重要箇所を参照できる(初動の安定化)。
- 中盤:デコーダーのマスク付き自己注意が「過去生成のみ」を参照して連続性を保ち、同時にクロス注意が入力のどこを参照するかを逐次選ぶことで、流暢さと入力忠実性の両立が図られる。
- 終わり:各ステップで更新される注意により、文末でも冒頭情報を再参照でき、要約や終局判断が整合的に行われる。
3. 意外な発見と限界
- 注意重みの可視化は教育的に強力だが、「重み = 完全な因果説明」ではない。モデル内の複雑な変換が最終出力に与える影響を重みだけで断定するのは危険(参考:[DataCamp](https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition))。
- 計算コストは二乗スケールで増えるため、長文処理はアルゴリズム的工夫(スパース注意や近似手法)が必要。
(短い表:生成の段階と主な注意機構)
| 段階 | 主な注意機構 | 効果 |
|---|---|---|
| 始まり | エンコーダー自己注意 → クロス注意(初回) | 入力全体から初期文脈を確保し、最初の単語選択を安定化 |
| 中盤 | デコーダーのマスク付き自己注意 + クロス注意 | 過去との整合性を保ちつつ入力参照で意味を維持 |
| 終わり | クロス注意の再参照・多層集約 | 重要情報の再利用で要約的な終端判断を支援 |
参考資料:Jay Alammar(図解)[https://jalammar.github.io/illustrated-transformer/], Vitalflux(計算ワークフロー)[https://vitalflux.com/attention-mechanism-workflow-example/], DataCamp(直感と課題)[https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition]
### より深い分析と解釈
「なぜAttentionが始まりから終わりまで機能するのか?」を三段階で掘り下げます。
1段階目(なぜ長距離依存を扱えるのか)
- なぜ:QueryとKeyの類似度で任意のトークン同士を直接比較できるから。
- 深掘り:RNNのように逐次的に情報を運ぶ必要がなく、並列に全トークンを見渡して「必要な箇所だけ取り出す」ため、文頭と文末の距離が問題にならない。
2段階目(なぜ生成の整合性が保たれるのか)
- なぜ:デコーダーのマスク付き自己注意が未来情報を遮断し、生成済み部分のみを根拠に次を決めるから。
- 深掘り:この因果的制約は学習時の教師信号と推論時の生成過程の整合を保ち、文の一貫性(時制、代名詞の照応など)を支える基盤となる。
3段階目(なぜ入力への忠実性と流暢さを両立できるのか)
- なぜ:クロス注意がデコーダーの「今の問い(Query)」に対してエンコーダーのKey/Valueを照合し、必要な入力情報を逐次取り出すから。
- 深掘り:結果的に「マスク付き自己注意=生成の内部整合」「クロス注意=入力との一致」という役割分担が明確になり、両者を繰り返すことで開始から終わりまで意図した意味を保てる。
矛盾や想定外の挙動に対する弁証法的解釈
- 観察:注意重みが高い箇所に注目しても、必ずしも最終出力の決定要因とは言えない。
- 解釈A(慎重派):注意は“ヒント”であり、複数層・非線形変換の結果で出力が定まるため単独で因果を示さない。
- 解釈B(実用派):教育・デバッグ用途では注意可視化は十分に有益で、出力の説明可能性向上に寄与する。最も現実的なのは「重み可視化+介入実験(注意を操作して挙動を見る)」で因果性を検証する方法。
シナリオ分析(短文 vs 長文、ノイズあり等)
- 短文:注意の二乗コストは問題になりにくく、多頭注意で語義の曖昧さを容易に解決。
- 長文:計算負荷とメモリがボトルネック。重要情報が散らばる場合、適切なスパース化やメモリ圧縮手法が必要。
- ノイズ(誤った/無関係な入力):クロス注意が誤情報に引かれると脱線(hallucination)を招くため、事前の入力フィルタリングや信頼度計測が重要。
結論的示唆:Attentionは「動的に情報を引き出す検索フィルター」であり、その反復的適用(多層・多ヘッド・マスク付き・クロス注意)が生成の始まりから終わりまでの一貫性を生み出している。ただし可視化の解釈と計算負荷には注意が必要。
### 戦略的示唆(実践的アクション)
学習者(中高生)向けの短期〜中期の具体的アクションプラン:
A. まず体感する(1回〜数時間)
1) インタラクティブな図解を読む:Jay Alammarの解説を見て図を追う([https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/))。
2) 簡単な可視化サイトやノートブックで、1文ごとの注意マップを観察する(例:「代名詞の参照がどの単語に向くか」を比較)。
B. ハンズオン実験(半日〜1日) — 最小実験プロトコル
1) 例文を2つ用意(短文:代名詞あり、長文:情報が散らばるもの)。
2) 小さなTransformerモデル(Hugging Faceの小型モデル)をColabで読み込み。
3) 各生成ステップでのデコーダー自己注意とクロス注意の重みを可視化(可視化ライブラリやサンプルノートを使う)。
4) 結果を比較:どの単語に重みが移るか、生成の初期と終盤で重みはどう変わるかを観察。
→ これにより「始まりに参照した箇所が終盤で再参照される」様子が見えるはずです。参考:Vitalfluxのフロー解説([https://vitalflux.com/attention-mechanism-workflow-example/](https://vitalflux.com/attention-mechanism-workflow-example/))。
C. 教室やワークショップでの活動案(数時間)
- アナロジー演習:生徒をトークンに見立て、質問役(Query)と回答役(Value)を決めて、誰に注目するかを順に投票していく活動。注意の重みは得票数で示す。これで注意の動的性が体感できる。
D. 研究的/実務的に試すこと(中期〜長期)
- 注意ヘッドや層を減らして生成品質に与える影響を実験。ヘッドごとの役割分離の程度を観察することで「多頭の必要性」を定量的に評価できる。
- クロス注意の強さを弱めたときの「脱線(hallucination)」発生率を測り、入力保全の重要性を評価する。
- 長文に対しては、Sparse Attentionやリカレントメモリ付き手法で計算/品質のトレードオフを比較する(参考:[https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition](https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition))。
ツールと参考リンク(教育と実験の即効資源)
- 図解と可視化:The Illustrated Transformer [https://jalammar.github.io/illustrated-transformer/]
- 計算フロー解説:Vitalflux [https://vitalflux.com/attention-mechanism-workflow-example/]
- 直感と課題整理:DataCamp [https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition]
もし希望があれば、Colab用の最小ノートブック(短い例文でデコーダーの各ステップの注意マップを出す)を作成します。やってみたい例文(英→日、あるいは日本語の代名詞例)を教えてください。
### 今後の調査の提案
以下は継続的に深めるべき調査テーマのリストです。学習教材づくりから研究的検証まで幅を想定しています。
- 小スケールの可視化教材の作成(Colabノート+解説カード)と教育効果の評価
- 注意重みの「因果性検証」実験:注意を人工的に操作して生成出力がどう変わるかを定量化する研究
- クロス注意の弱化・強化実験:入力忠実性(hallucination発生率)との相関を定量化する調査
- 長文処理に向けた効率化手法の比較(Sparse Attention, Longformer系, メモリ圧縮など)の実用評価
- 多頭注意の役割分解:各ヘッドが捉える関係性(構文 vs 意味 vs 位置情報)を自動分類する試み
- 教育カリキュラム化:中高生向けのモジュール(比喩・実験・評価問題)を作り、学習理解度を測るフィールド実験
- 可視化ツールの改善:層・ヘッド・ステップを横断して見やすく比較できるインターフェース設計
必要ならば、上のいずれかのテーマについて具体的な実験設計(目的、手順、評価指標、必要ツール)を作成します。まずは「どのレベルで体験したいか(図解のみ/簡単なColabで実験/教育ワークショップ)を教えてください」。
📚 参考文献
参考文献の詳細は、ブラウザでページを表示してご確認ください。