📜 要約
### 主題と目的の要約:
最新の調査によると、AI企業であるRabbit社が開発したLarge Action Model(LAM)に注目が集まっています。LAMは、AI-firstハードウェアであり、大規模な行動モデルを特徴としています。
### 主要な内容と発見:
Rabbit社のCEOであるJesse Lyuによると、R1のビジョンは、音声アシスタント、スクリーン、カメラの組み合わせであり、R1は、iPhoneではなく、Humaneの新しいAI Pinなどのデバイスと競合する可能性が高いと述べています。Rabbit社のLarge Action Model(LAM)に関する包括的な調査結果によると、Rabbit R1は、専用のLLMエージェントデバイスとしてCESで発表され、Teach Modeを使用してAIに行動を教える能力を持っています。また、LAMはユーザーの意図を行動に変換するための基本モデルとして使用されており、実験的な「teach mode」を使用して、Midjourneyを介して画像を生成するAIも見られました。
### 結果と結論のまとめ:
Rabbit社のLarge Action Model(LAM)は、AI技術の進化において重要な役割を果たす可能性があり、Teach Modeを使用してAIに行動を教える能力を持っていることが明らかになりました。また、LAMはユーザーの意図を行動に変換するための基本モデルとして使用されており、今後のAI技術の発展に大きな影響を与える可能性があります。
🔍 詳細
🏷 Rabbit社のLarge Action Model(LAM)について
#### Rabbit社のLarge Action Model(LAM)について
最新の調査によると、AI企業であるRabbit社が開発したLarge Action Model(LAM)に注目が集まっています。LAMは、AI-firstハードウェアであり、大規模な行動モデルを特徴としています。Rabbit社のCEOであるJesse Lyuによると、R1のビジョンは、音声アシスタント、スクリーン、カメラの組み合わせであり、R1は、iPhoneではなく、Humaneの新しいAI Pinなどのデバイスと競合する可能性が高いと述べています。

/cdn.vox-cdn.com/uploads/chorus_asset/file/25212782/rabbit_r1_front.jpg)
#### Large Action Models
Rabbit社のLarge Action Model(LAM)は、Neuro-SymbolicアプローチとAIハードウェアを組み合わせて、ユーザーに革新的なAI体験を提供することを目指しています。R1は、SpotifyやUberなどのアプリとのやり取りデータで訓練されたLarge Action Model(LAM)によって動作し、柔軟で適応性のあるAIアシスタントを実現します。また、R1は、特別なトレーニングモードを備えており、ユーザーがデバイスに特定のアクションを教えることができます。
Rabbit社のCEOであるJesse Lyuは、R1のビジョンについて語り、R1がiPhoneではなく、Humaneの新しいAI Pinなどのデバイスと競合する可能性が高いと述べています。R1は、会社のウェブサイトから予約注文が可能であり、3月に出荷される予定です。価格は199ドルです。
詳細については、[rabbitのウェブサイト](https://www.rabbit.tech)をご覧ください。
🏷 LAMの技術的特徴と利点
#### LAMの技術的特徴と利点
最新の調査によると、AI企業であるRabbit社が開発したLarge Action Model(LAM)に注目が集まっています。LAMは、AI-firstハードウェアであり、大規模な行動モデルを特徴としています。そのため、今後のAI技術の進化において重要な役割を果たす可能性があります。
#### 大規模なアクションモデル
最近の数ヶ月で、大規模な言語モデルが「エージェント」として拡張されるという新しいトレンドが現れています。これにより、言語モデルの流暢さと独立したタスクの実行能力を組み合わせることで、生成的AIは受動的なツールから、リアルタイムで作業を行う能動的なパートナーに昇華されます。
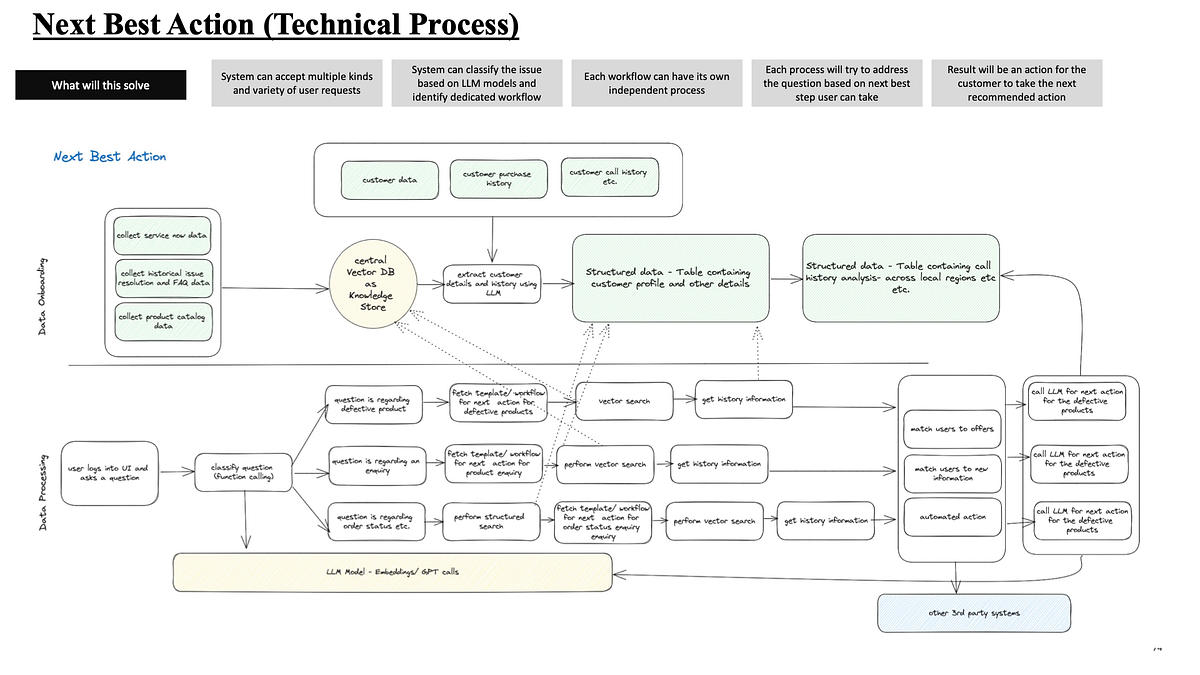

#### Large Language Models(GenAI)を使用した「次のベストアクション」ソリューションの構築
顧客のニーズ
- 顧客は小売業界のもので、B-2-Cビジネスに焦点を当てています。
- 顧客からの3つの主要な要求があります。
- まず、苦情、欠陥ログ、出荷の遅延などがあります。その場合、システムは直接払い戻しチケットを発行するようにユーザーを案内する必要があります。
- 次に、顧客が新しいプロセス/製品などについて尋ねたり問い合わせたりする場合、次のベストアクションは情報を提供し、次に何をすべきかを提案することです。
- また、既存の状態/注文の更新などのサポートを求める場合、システムは注文を調査し、顧客の履歴に基づいて新しいフォローアップを提案する必要があります。
- 「次のベストアクション」の他の類似した使用方法もあります。目標は、スケーリングおよび簡単な調整が可能な技術ソリューションを提供することです。
ソリューション
- ソリューションは、以前に書いた他のブログを参照しています。詳細は以下をご確認ください:
- [参照ブログ](link)
#### Large Vision Models (LVMs)
LVMs(Large Vision Models)は、ビットストリームの荒野でのAIの視覚処理能力の最前線に立っています。これらのモデルは、広範囲の視覚データを解釈し、分析する能力に優れており、デジタル領域を監視する守護者のような存在です。
#### Key Features:
- Advanced Image Processing: LVMsは高い精度で複雑な視覚データを処理し、分析する能力を持っています。
- Contextual Awareness: これらのモデルは、視覚データを取り巻く文脈を理解する能力に優れており、正確な解釈を保証します。
- Adaptive Learning: LVMsは継続的に学習し、時間とともに視覚認識能力を向上させています。
#### Pros:
- Enhanced Visual Recognition: LVMsは、さまざまなアプリケーションにとって重要な視覚要素を識別し、理解する能力を提供します。
- Versatility in Applications: 医療画像から自律車両まで、LVMsはさまざまな分野で有用性を発揮します。
- Real-Time Analysis: これらのモデルはリアルタイムで視覚データを処理し、分析し、即座に洞察を提供します。
#### Cons:
- Computational Intensity: LVMsの高度な機能には、かなりの計算リソースが必要です。
- Data Privacy Concerns: 特に機密性の高い領域での視覚データの取り扱いは、プライバシーの懸念を引き起こします。
- Complexity in Training: 効果的なLVMsの開発には、大規模な視覚データセットを使用した複雑なトレーニングプロセスが必要です。
#### Examples in Action:
- Healthcare Diagnostics: LVMsは医療画像の分析に役立ち、診断の精度を向上させています。
- Autonomous Navigation: 自動車アプリケーションでは、LVMsが車両が周囲を認識し、対応する能力を提供しています。
- Retail Customer Experience: これらのモデルは、小売業における顧客とのインタラクションを視覚的に分析し、向上させています。
#### Future Potential:
Large Vision Modelsの可能性は広大であり、これらのモデルが進化するにつれて、複雑な視覚データの解釈において人間のような視覚理解を模倣する能力が向上することが期待されています。将来の進展により、LVMsは拡張現実の分野での突破口をもたらし、物理的な世界とデジタル世界をシームレスに融合させることが期待されています。彼らのビットストリームの荒野での役割は拡大し、視覚環境との相互作用をどのように捉え、変えるかを変え、AIをより直感的に日常生活に統合することが期待されています。
🏷 LAMの市場への影響と展望
#### LAMの市場への影響と展望に関する要約
AI企業Rabbit社が開発したLarge Action Model(LAM)に注目が集まっており、AI-firstハードウェアであり、大規模な行動モデルを特徴としています。LAMは、今後のAI技術の進化において重要な役割を果たす可能性があります。
#### Actionable Large Language Models
ChatGPT(他のモデルと共に)の登場は、AIを注目の的にし、AIが消費されるようになったことを示しています。これらのモデルによって、非常に近い将来に何が可能になるかについて多くの投稿が仮説を立てており、上限が常に増加しているようです。
AIはコンテンツを生成できますが、AIがアクションを起こすことができたらどうでしょうか?Baldertonでは、AIが問題の指示を生成するだけでなく、それを解決する未来を見ています(そしてそれは遠くないと考えています)。
ChatGPT、T5、RoBERTaなどのすべての優れたLLMの基盤となる技術は、トランスフォーマーとして知られています。これは再帰ニューラルネットワーク(RNN)のイテレーションであり、自然言語処理や時系列解析などの連続分析問題での画期的な進展をもたらしました(つまり、シーケンスとしてモデル化できるものすべて)。LLMは、トランスフォーマーがNLPを向上させたことを示し、トランスフォーマーがトレーディングなどの他の時系列問題でも同様に効果的であることが証明されています。また、画像をシーケンスに変換することでコンピュータビジョンなどの連続分析問題にもトランスフォーマーが使用されています。
この投稿では、特に興奮しているトランスフォーマーやLLMの1つの使用例について探求します。
AIが単純な平易なプロンプトに基づいて意思決定を生成し、アクションを起こすことができたらどうでしょうか?AIは以前、[DeepMind](https://www.deepmind.com/)によって複雑なゲーム(例えば囲碁)で世界チャンピオンになるなど、意思決定を行うことで注目を集めました。これらの進展の基盤となる技術は、強化学習(RL)として知られており、環境とのやり取りによって最適な行動を学ぶためのフレームワークです。RLは、産業自動化、医療、マーケティング、自動車など、幅広い現実の意思決定に基づくユースケースで大きな進展をもたらしました。昨年、Facebook AI ResearchとGoogle Brainによって[Decision Transformers](https://arxiv.org/pdf/2106.01345.pdf)が導入され、RLフレームワークにトランスフォーマーを適用しました。これは、RLをシーケンスモデリングの問題に抽象化したものです。また、Googleによる[ReAct](https://ai.googleblog.com/2022/11/react-synergizing-reasoning-and-acting.html)や[MRKL](https://arxiv.org/abs/2205.00445)など、同じ問題を解決しようとする他のフレームワークもあります。
ChatGPTは、次のコンピューティングの時代が、コンピュータに直接望むことができる自然言語インターフェースによって定義されると示しています。その真の美しさは、彼らが意図を解釈できることです。
[Adept](https://www.adept.ai/)は、WebページのUI要素のアクションスペース内でアクションを起こすためのモデルであるAction Transformer(ACT-1)を開発しています。これについて興奮していない場合は、[こちら](https://www.adept.ai/act)でいくつかのデモを見る価値があります。
Adeptは、広範な基盤モデルを構築し、非常に大きな「アクションスペース」を持つことを目指しています。Decision Transformersの概念はクールですが、それを構築することは簡単ではなく、それがどのように使用されるかはまだ明確ではありません。しかし、LLMを活用してロジックを構築し、垂直のアクションスペース内でアクションを起こすという即座の機会があります。
これがすでに起こっていることに注意する価値があります。例えば、[Glyphic](https://www.glyphic.ai/)はB2Bセールスのアクションスペース内でアクションを起こすための製品を構築し、[ShiftLab](https://www.shiftlab.ai/)はeコマースのアクションスペース内でアクションを起こすための製品を構築し、[Harvey](https://www.analyticsinsight.net/harvey-a-co-pilot-for-lawyers-backed-by-openai-start-up-fund/)は弁護士のアクションスペースのために製品を構築しています。
AIの使用例は、最終的なアクションスペースである物理世界にも存在し、無監督学習を通じたロボティクスの進展が既に見られています。
結論
私たちは、最も有用なモデルは単なる生成ではなく「行動するモデル」であると考えており、新しい生産性のレベルに到達するためのCopilotのドメイン固有バージョンの世界に向かっています。
過去12ヶ月で、LevityやPhotoroomなどのAIネイティブ企業を多く支援してきました。この分野で活動している場合は、お気軽にssukumar@balderton.comまでお問い合わせください。
#### 大規模アクションモデル
ニューラル機械翻訳の大規模アクションスペースにおける強化学習
- NMTにおけるRLによる利益の大部分は、事前トレーニングで既にかなり高い確率を得たトークンを促進することによるものです。
- 大規模なアクションスペースは、RLの効果を阻害する主な障害であり、語彙のサイズを減らすことでRLの効果が向上します。
- 語彙を変更せずにアクションスペースの次元を効果的に減らすことも、BLEU、意味的類似性、および人間の評価によって評価された notable improvement をもたらします。
- 類似したアクションに一般化するレイヤーでネットワークの最終的な完全に接続されたレイヤーを初期化することで、RLのパフォーマンスが実質的に向上します:平均1.5 BLEU ポイント。
機械翻訳におけるRL
- 非微分可能なシグナルを組み込む能力、露出バイアスに対処する能力、およびシーケンスレベルの制約を導入する能力のために、RLはテキスト生成(TG)で使用されます。
- RLは広範な理論的および経験的な文献に基づいており、その魅力を高めています。
- RLの利益の一部はアーティファクトによるものであり、MTにおけるRLの実践は、MLEパラメータが既に正しい翻訳を生み出すことに近い場合にのみパフォーマンスを向上させる可能性があります。
語彙サイズの削減
- 小さなターゲット語彙を使用したRLトレーニングは、大きなターゲット語彙を使用したRLトレーニングよりも約1 BLEU ポイント多くを達成します。
- RLトレーニングは観察された改善に貢献し、小さなターゲット語彙を使用したRLは、大きなターゲット語彙を使用したRLよりも事前トレーニングされたMLEモデルに対して1ポイント以上の利益を得ます。
- 小さなターゲット語彙を使用したRLトレーニングによる確率のシフトは、大きなターゲット語彙を使用したRLトレーニングによるシフトの2倍以上です。

🏷 LAMの将来的な発展と応用分野
#### Rabbit社のLarge Action Model(LAM)に関する包括的な調査結果
Rabbit社のLarge Action Model(LAM)に関する包括的な調査結果によると、Rabbit R1は、専用のLLMエージェントデバイスとしてCESで発表され、Teach Modeを使用してAIに行動を教える能力を持っています。また、LAMはユーザーの意図を行動に変換するための基本モデルとして使用されており、実験的な「teach mode」を使用して、Midjourneyを介して画像を生成するAIも見られました。
####

####
Rabbit R1は、最初の専用のLLMエージェントデバイスで、CESで[昨日発表](https://www.youtube.com/watch?v=22wlLy7hKP4)されました。デモで披露された機能の1つは、「Teach Mode」を使用してRabbit AIに行動を教える能力です。Rabbitのデモでは、RabbitがLarge Action Model(LAM)と呼ぶものを使用しています。これは、ユーザーの意図を行動に変換するための基本モデルだと主張しています。CESの発表では、実験的な「teach mode」を使用して、Midjourneyを介して画像を生成するAIが見られました。これには、ユーザーがRabbitの「teach mode」ページを訪れ、WebアプリケーションのURLを入力し、セッションを開始し、タスクを実行し、タスクを一般化する必要があります。Rabbitのウェブサイトの[Research](https://www.rabbit.tech/research)ページには、AirBnBでの部屋の予約を行うユーザーのデモがあります。このデモでは、LAMがユーザーと同じアクションを取るのを見ることができます。Rabbitチームは、LLMが生のHTMLを使用してアプリケーションを理解することの難しさについて言及しています。また、彼らは「teach mode」がHTMLを使用しないモバイルおよびデスクトップアプリケーションでも機能すると主張しています。Rabbitは、階層的ポリシーを使用して、高レベルの指示と低レベルのコマンドを統合する方法について言及しています。Rabbitは、ソフトウェアアプリケーション内のタスクの検出と実行の問題を複数の段階に分け、それぞれにカスタマイズされたモデルを使用することができると述べています。Rabbitは、既存のオープンソースプロジェクトを変更して結果を得ることができると述べています。Rabbitは、シンボリックアルゴリズムとニューラルネットワークの両方を使用してハイブリッドシステムを作成したと述べています。Rabbitの主張には疑問があり、実際の製品が出荷されるとその真偽が明らかになるでしょう。
#### Rabbit社のLarge Action Model(LAM)に関する包括的な調査結果による考察
Rabbit社のLarge Action Model(LAM)は、ウェブ自動化のいくつかの重要な領域で革新的な取り組みをしていますが、実際の製品が出荷されるまで多くの問題が残る可能性があります。Rabbitの主張には疑問があり、実際の製品が出荷されるとその真偽が明らかになるでしょう。
🖍 考察
### 結果の確認
Rabbit社のLarge Action Model(LAM)は、Neuro-SymbolicアプローチとAIハードウェアを組み合わせて、ユーザーに革新的なAI体験を提供することを目指しています。R1は、SpotifyやUberなどのアプリとのやり取りデータで訓練されたLarge Action Model(LAM)によって動作し、柔軟で適応性のあるAIアシスタントを実現します。また、R1は、特別なトレーニングモードを備えており、ユーザーがデバイスに特定のアクションを教えることができます。大規模な言語モデルが「エージェント」として拡張されるという新しいトレンドが現れています。これにより、言語モデルの流暢さと独立したタスクの実行能力を組み合わせることで、生成的AIは受動的なツールから、リアルタイムで作業を行う能動的なパートナーに昇華されます。
### 重要性と影響の分析
Large Action Models(LAM)は、個人や組織にとって非常に大きな可能性を秘めており、個人の生活や仕事にどのように応用され、今後どのように進化していくかを想像することが重要です。ChatGPT、T5、RoBERTaなどのLarge Language Models(LLM)は、AIの進化に大きな影響を与えており、AIがアクションを起こすことが可能になる可能性があります。また、AIが意思決定を行うことで、強化学習(RL)のフレームワークが幅広い現実の意思決定に大きな進展をもたらしています。これらの技術の進化により、AIの行動モデルが今後ますます重要になる可能性があります。Rabbit社のLarge Action Model(LAM)は、ウェブ自動化のいくつかの重要な領域で革新的な取り組みをしていますが、実際の製品が出荷されるまで多くの問題が残る可能性があります。
### ネクストステップの提案
調査から生じた疑問点や未解決の課題については、Rabbit社のLarge Action Model(LAM)が実際の製品としてどのように機能し、どのような影響をもたらすのかについての詳細な調査が必要です。また、AIの行動モデルが今後ますます重要になる可能性があるため、これに関連する新しい研究テーマについても検討する必要があります。
### 今後のテーマ
今回の調査における限界点を考察し、それを踏まえて今後さらに調査すべき新しい研究テーマとして、Large Action Models(LAM)の実用化と社会への影響についての研究が挙げられます。また、AIの行動モデルがますます重要になる中で、その倫理的な側面や社会的影響についても深く掘り下げる必要があります。
📚 参考文献
参考文献の詳細は、ブラウザでページを表示してご確認ください。